After disrupting lots of businesses and making money, Maze ransomware has now announced its departure. However, there won’t be a
Maze Ransomware Announces Departure – Replacements Already Available on Latest Hacking News.
After disrupting lots of businesses and making money, Maze ransomware has now announced its departure. However, there won’t be a
Maze Ransomware Announces Departure – Replacements Already Available on Latest Hacking News.
Reportedly, the faulty implementation of link previews has made numerous chat apps vulnerable to cyber attacks. These apps include Facebook
Link Previews Make Chat Apps Vulnerable To Data Leak And RCE Attacks on Latest Hacking News.
A small Israel-based security firm, Security Joes, recently spotted a vulnerability in smart irrigation systems. These included around 100 systems
Smart Irrigation Systems Left Wide Open to Abuse on Latest Hacking News.
New ESET Threat Report is out – Are things in IoT security finally changing? – 5 spooky tales of data breaches
The post Week in security with Tony Anscombe appeared first on WeLiveSecurity
As Election Day draws near, here's a snapshot of how this election cycle is faring in the hands of the would-be digitally meddlesome
The post Election (in)security: What you may have missed appeared first on WeLiveSecurity
Just in time for Halloween, we look at the haunting reality of data breaches and highlight five tales that spooked not only the cyber-world
The post 5 scary data breaches that shook the world appeared first on WeLiveSecurity
Online data privacy is a prominent topic in the digital space. The increased transfer of data from analog to digital
10 Best Practices for Data Encryption on Latest Hacking News.
Introduction Not only is data protection essential to those needing regulatory compliance across multiple laws and standards but it is
Why Do You Need Continuous Data Protection on Latest Hacking News.
In app development, there is a necessary phase called performance test. What you do in this phase is try to
Performance Testing vs. Load Testing vs. Stress Testing on Latest Hacking News.
Before you just outsource your web design to a front-end development agency, it would not hurt to have some basic
How to Design a Website? 3 Important Tips on Latest Hacking News.
Once again, malicious apps barraging users with ads have flooded the Android Play Store. This time, the researchers spotted 21
21 More Android Apps Part Of HiddenAds Campaign – 3 Still Available On Play Store on Latest Hacking News.
The patch for the critical flaw that allows malware to spread across machines without any user interaction was released months ago
The post Over 100,000 machines remain vulnerable to SMBGhost exploitation appeared first on WeLiveSecurity
Better IoT security and data protection are long overdue. Will they go from an afterthought to everyone's priority any time soon?
The post IoT security: Are we finally turning the corner? appeared first on WeLiveSecurity
A view of the Q3 2020 threat landscape as seen by ESET telemetry and from the perspective of ESET threat detection and research experts
The post ESET Threat Report Q3 2020 appeared first on WeLiveSecurity

In this article, we’ll discuss how to use higher-order components to keep your React applications tidy, well-structured and easy to maintain. We’ll discuss how pure functions keep code clean and how these same principles can be applied to React components.
A function is considered pure if it adheres to the following properties:
For example, the add function below is pure:
function add(x, y) {
return x + y;
}
However, the function badAdd below is impure:
let y = 2;
function badAdd(x) {
return x + y;
}
This function is not pure because it references data that it hasn’t directly been given. As a result, it’s possible to call this function with the same input and get different output:
let y = 2;
badAdd(3) // 5
y = 3;
badAdd(3) // 6
To read more about pure functions you can read “An introduction to reasonably pure programming” by Mark Brown.
Whilst pure functions are very useful, and make debugging and testing an application much easier, occasionally you’ll need to create impure functions that have side effects, or modify the behavior of an existing function that you’re unable to access directly (a function from a library, for example). To enable this, we need to look at higher-order functions.
A higher-order function is a function that returns another function when it’s called. Often they also take a function as an argument, but this isn’t required for a function to be considered higher-order.
Let’s say we have our add function from above, and we want to write some code so that when we call it, we log the result to the console before returning the result. We’re unable to edit the add function, so instead we can create a new function:
function addAndLog(x, y) {
const result = add(x, y);
console.log(`Result: ${result}`);
return result;
}
We decide that logging results of functions is useful, and now we want to do the same with a subtract function. Rather than duplicate the above, we could write a higher-order function that can take a function and return a new function that calls the given function and logs the result before then returning it:
function logAndReturn(func) {
return function(...args) {
const result = func(...args)
console.log('Result', result);
return result;
}
}
Now we can take this function and use it to add logging to add and subtract:
const addAndLog = logAndReturn(add);
addAndLog(4, 4) // 8 is returned, ‘Result 8’ is logged
const subtractAndLog = logAndReturn(subtract);
subtractAndLog(4, 3) // 1 is returned, ‘Result 1’ is logged;
logAndReturn is a higher-order function because it takes a function as its argument and returns a new function that we can call. These are really useful for wrapping existing functions that you can’t change in behavior. For more information on this, check M. David Green’s article “Higher-Order Functions in JavaScript”, which goes into much more detail on the subject.
See the Pen
Higher Order Functions by SitePoint (@SitePoint)
on CodePen.
Moving into React land, we can use the same logic as above to take existing React components and give them some extra behaviors.
Note: with the introduction of React Hooks, released in React 16.8, higher-order functions became slightly less useful because hooks enabled behavior sharing without the need for extra components. That said, they are still a useful tool to have in your belt.
In this section, we’re going to use React Router, the de facto routing solution for React. If you’d like to get started with the library, I highly recommend the React Router documentation as the best place to get started.
React Router provides a <NavLink> component that’s used to link between pages in a React application. One of the properties that this <NavLink> component takes is activeClassName. When a <NavLink> has this property and it’s currently active (the user is on a URL that the link points to), the component will be given this class, enabling the developer to style it.
This is a really useful feature, and in our hypothetical application we decide that we always want to use this property. However, after doing so we quickly discover that this is making all our <NavLink> components very verbose:
<NavLink to="/" activeClassName="active-link">Home</NavLink>
<NavLink to="/about" activeClassName="active-link">About</NavLink>
<NavLink to="/contact" activeClassName="active-link">Contact</NavLink>
Notice that we’re having to repeat the class name property every time. Not only does this make our components verbose, it also means that if we decide to change the class name we’ve got to do it in a lot of places.
Instead, we can write a component that wraps the <NavLink> component:
const AppLink = (props) => {
return (
<NavLink to={props.to} activeClassName="active-link">
{props.children}
</NavLink>
);
};
And now we can use this component, which tidies up our links:
<AppLink to="/home" exact>Home</AppLink>
<AppLink to="/about">About</AppLink>
<AppLink to="/contact">Contact</AppLink>
In the React ecosystem, these components are known as higher-order components, because they take an existing component and manipulate it slightly without changing the existing component. You can also think of these as wrapper components, but you’ll find them commonly referred to as higher-order components in React-based content.
Continue reading Higher-order Components: A React Application Design Pattern on SitePoint.
Are you trying to find a way for unblocking Netflix from everywhere and accessing more movie titles and Tv shows?
The best free VPN for unblocking Netflix 2020 on Latest Hacking News.
When it comes to TV entertainment, people have different preferences. Some people want to just sit back and relax while
Is Roku Worth It? How Can I Link My Roku With My Cable Internet? on Latest Hacking News.
Some programmers are wondering why others have switched to Ruby. Perhaps, you are also curious about this sudden trend in
10 Reasons to Switch to Ruby on Latest Hacking News.

Almost every application needs to accept user input at some point, and this is usually achieved with the venerable HTML form and its collection of input controls. If you’ve recently started learning React, you’ve probably arrived at the point where you’re now thinking, “So how do I work with forms?”
This article will walk you through the basics of using forms in React to allow users to add or edit information. We’ll look at two different ways of working with input controls and the pros and cons of each. We’ll also take a look at how to handle validation, and some third-party libraries for more advanced use cases.
The most basic way of working with forms in React is to use what are referred to as “uncontrolled” form inputs. What this means is that React doesn’t track the input’s state. HTML input elements naturally keep track of their own state as part of the DOM, and so when the form is submitted we have to read the values from the DOM elements themselves.
In order to do this, React allows us to create a “ref” (reference) to associate with an element, giving access to the underlying DOM node. Let’s see how to do this:
class SimpleForm extends React.Component {
constructor(props) {
super(props);
// create a ref to store the DOM element
this.nameEl = React.createRef();
this.handleSubmit = this.handleSubmit.bind(this);
}
handleSubmit(e) {
e.preventDefault();
alert(this.nameEl.current.value);
}
render() {
return (
<form onSubmit={this.handleSubmit}>
<label>Name:
<input type="text" ref={this.nameEl} />
</label>
<input type="submit" name="Submit" />
</form>
)
}
}
As you can see above, for a class-based component you initialize a new ref in the constructor by calling React.createRef, assigning it to an instance property so it’s available for the lifetime of the component.
In order to associate the ref with an input, it’s passed to the element as the special ref attribute. Once this is done, the input’s underlying DOM node can be accessed via this.nameEl.current.
Let’s see how this looks in a functional component:
function SimpleForm(props) {
const nameEl = React.useRef(null);
const handleSubmit = e => {
e.preventDefault();
alert(nameEl.current.value);
};
return (
<form onSubmit={handleSubmit}>
<label>Name:
<input type="text" ref={nameEl} />
</label>
<input type="submit" name="Submit" />
</form>
);
}
There’s not a lot of difference here, other than swapping out createRef for the useRef hook.
function LoginForm(props) {
const nameEl = React.useRef(null);
const passwordEl = React.useRef(null);
const rememberMeEl = React.useRef(null);
const handleSubmit = e => {
e.preventDefault();
const data = {
username: nameEl.current.value,
password: passwordEl.current.value,
rememberMe: rememberMeEl.current.checked,
}
// Submit form details to login endpoint etc.
// ...
};
return (
<form onSubmit={handleSubmit}>
<input type="text" placeholder="username" ref={nameEl} />
<input type="password" placeholder="password" ref={passwordEl} />
<label>
<input type="checkbox" ref={rememberMeEl} />
Remember me
</label>
<button type="submit" className="myButton">Login</button>
</form>
);
}
While uncontrolled inputs work fine for quick and simple forms, they do have some drawbacks. As you might have noticed from the code above, we have to read the value from the input element whenever we want it. This means we can’t provide instant validation on the field as the user types, nor can we do things like enforce a custom input format, conditionally show or hide form elements, or disable/enable the submit button.
Fortunately, there’s a more sophisticated way to handle inputs in React.
An input is said to be “controlled” when React is responsible for maintaining and setting its state. The state is kept in sync with the input’s value, meaning that changing the input will update the state, and updating the state will change the input.
Let’s see what that looks like with an example:
class ControlledInput extends React.Component {
constructor(props) {
super(props);
this.state = { name: '' };
this.handleInput = this.handleInput.bind(this);
}
handleInput(event) {
this.setState({
name: event.target.value
});
}
render() {
return (
<input type="text" value={this.state.name} onChange={this.handleInput} />
);
}
}
As you can see, we set up a kind of circular data flow: state to input value, on change event to state, and back again. This loop allows us a lot of control over the input, as we can react to changes to the value on the fly. Because of this, controlled inputs don’t suffer from the limitations of uncontrolled ones, opening up the follow possibilities:
As I mentioned above, the continuous update loop of controlled components makes it possible to perform continuous validation on inputs as the user types. A handler attached to an input’s onChange event will be fired on every keystroke, allowing you to instantly validate or format the value.
Continue reading Working with Forms in React on SitePoint.
Popular PDF service provider Nitro PDF has recently suffered a massive data breach. While, they apparently strive to downplay the
Nitro PDF Suffered A Data Breach Impacting Google, Apple, Amazon, And More on Latest Hacking News.

The React ecosystem has evolved into a growing list of dev tools and libraries. The plethora of tools is a true testament to React’s popularity. For devs, it can be a dizzying exercise to navigate this maze that changes at neck-breaking speed. To help navigate your course, below is a list of essential React tools, techniques and skills for 2020.
While not strictly a tool, any developer working with React in 2020 needs to be familiar with hooks. These are a new addition to React as of version 16.8 which unlock useful features in function components. For example, the useState hook allows a function component to have its own state, whereas useEffect allows you to perform side effects after the initial render — for example, manipulating the DOM or data fetching. Hooks can be used to replicate lifecycle methods in functional components and allow you to share code between components.
The following basic hooks are available:
Pros:
Cons:
If you’d like to find out more about hooks, then check out our tutorial, “React Hooks: How to Get Started & Build Your Own”.
With the advent of hooks, function components — a declarative way to create JSX markup without using a class — are becoming more popular than ever. They embrace the functional paradigm because they don’t manage state in lifecycle methods. This emphasizes focus on the UI markup without much logic. Because the component relies on props, it becomes easier to test. Props have a one-to-one relationship with the rendered output.
This is what a functional component looks like in React:
function Welcome(props) {
return <h1>Hello, {props.name}</h1>;
}
Pros:
Cons:
Create React App is the quintessential tool for firing up a new React project. It manages all React dependencies via a single npm package. No more dealing with Babel, webpack, and the rest. All it takes is one command to set up a local development environment, with React, JSX, and ES6 support. But that’s not all. Create React App also offers hot module reloading (your changes are immediately reflected in the browser when developing), automatic code linting, a test runner and a build script to bundle JS, CSS, and images for production.
It’s easy to get started:
npx create-react-app my-killer-app
And it’s even easier to upgrade later. The entire dependency tool chain gets upgraded with react-scripts in package.json:
npm i react-scripts@latest
Pros:
Cons:
If you’d like to find out more about using Create React App, please consult our tutorial, “Create React App – Get React Projects Ready Fast”.
Starting from version react-scripts@0.2.3 or higher, it’s possible to proxy API requests. This allows the back-end API and local Create React App project to co-exist. From the client side, making a request to /my-killer-api/get-data routes the request through the proxy server. This seamless integration works both in local dev and post-build. If local dev runs on port localhost:3000, then API requests go through the proxy server. Once you deploy static assets, it goes through whatever back end hosts these assets.
To set a proxy server in package.json:
"proxy": "http://localhost/my-killer-api-base-url"
If the back-end API is hosted with a relative path, set the home page:
"homepage": "/relative-path"
Pros:
Con
PropTypes declares the type intended for the React component and documents its intent. This shows a warning in local dev if the types don’t match. It supports all JavaScript primitives such as Boolean, Number, and String. It can document which props are required via isRequired.
For example:
import PropTypes;
MyComponent.propTypes = {
boolProperty: PropTypes.bool,
numberProperty: PropTypes.number,
requiredProperty: PropTypes.string.isRequired
};
Pros:
Cons:
JavaScript that scales for React projects with compile type checking. This supports all React libraries and tools with type declarations. It’s a superset of JavaScript, so it’s possible to opt out of the type checker. This both documents intent and fails the build when it doesn’t match. In Create React App projects, turn it on by passing in --template typescript when creating your app. TypeScript support is available starting from version react-script@2.1.0.
To declare a prop type:
interface MyComponentProps {
boolProp?: boolean; // optional
numberProp?: number; // optional
requiredProp: string;
}
Pros:
Cons:
If you’d like to find out more about using TypeScript with React, check out “React with TypeScript: Best Practices”.
Predictable state management container for JavaScript apps. This tool comes with a store that manages state data. State mutation is only possible via a dispatch message. The message object contains a type that signals to the reducer which mutation to fire. The recommendation is to keep everything in the app in a single store. Redux supports multiple reducers in a single store. Reducers have a one-to-one relationship between input parameters and output state. This makes reducers pure functions.
A typical reducer that mutates state might look like this:
const simpleReducer = (state = {}, action) => {
switch (action.type) {
case 'SIMPLE_UPDATE_DATA':
return {...state, data: action.payload};
default:
return state;
}
};
Pros:
Cons:
If you want to use Redux in your React apps, you’ll soon discover the official React bindings for Redux. This comes in two main modules: Provider and connect. The Provider is a React component with a store prop. This prop is how a single store hooks up to the JSX markup. The connect function takes in two parameters: mapStateToProps, and mapDispatchToProps. This is where state management from Redux ties into component props. As state mutates, or dispatches fire, bindings take care of setting state in React.
This is how a connect might look:
import { bindActionCreators } from 'redux';
import { connect } from 'react-redux';
const mapStateToProps = (state) => state.simple;
const mapDispatchToProps = (dispatch) =>
bindActionCreators({() => ({type: 'SIMPLE_UPDATE_DATA'})}, dispatch);
connect(mapStateToProps, mapDispatchToProps)(SimpleComponent);
Pros:
Cons:
It should also be noted that, with the introduction of hooks and React’s Context API, it’s possible to replace Redux in some React applications. You can read more about that in “How to Replace Redux with React Hooks and the Context API”.
React Router is the de facto standard routing library for React. When you need to navigate through a React application with multiple views, you’ll need a router to manage the URLs. React Router takes care of that, keeping your application UI and the URL in sync.
The library comprises three packages: react-router, react-router-dom, and react-router-native. The core package for the router is react-router, whereas the other two are environment specific. You should use react-router-dom if you’re building a website, and react-router-native if you’re building a React Native app.
Recent versions of React Router have introduced hooks, which let you access the state of the router and perform navigation from inside your components, as well as a newer route rendering pattern:
<Route path="/">
<Home />
</Route>
If you’d like to find out more about what React Router can do, please see “React Router v5: The Complete Guide”.
Pros:
Cons:
Continue reading 20 Essential React Tools for 2020 on SitePoint.

React Router is the de facto standard routing library for React. When you need to navigate through a React application with multiple views, you’ll need a router to manage the URLs. React Router takes care of that, keeping your application UI and the URL in sync.
This tutorial introduces you to React Router v5 and a whole lot of things you can do with it.
React is a popular library for creating single-page applications (SPAs) that are rendered on the client side. An SPA might have multiple views (aka pages), and unlike conventional multi-page apps, navigating through these views shouldn’t result in the entire page being reloaded. Instead, we want the views to be rendered inline within the current page. The end user, who’s accustomed to multi-page apps, expects the following features to be present in an SPA:
www.example.com/products.example.com/products/shoes/101, where 101 is the product ID.Routing is the process of keeping the browser URL in sync with what’s being rendered on the page. React Router lets you handle routing declaratively. The declarative routing approach allows you to control the data flow in your application, by saying “the route should look like this”:
<Route path="/about">
<About />
</Route>
You can place your <Route> component anywhere you want your route to be rendered. Since <Route>, <Link> and all the other React Router APIs that we’ll be dealing with are just components, you can easily get up and running with routing in React.
Note: there’s a common misconception that React Router is an official routing solution developed by Facebook. In reality, it’s a third-party library that’s widely popular for its design and simplicity.
This tutorial is divided into different sections. First, we’ll set up React and React Router using npm. Then we’ll jump right into some React Router basics. You’ll find different code demonstrations of React Router in action. The examples covered in this tutorial include:
All the concepts connected with building these routes will be discussed along the way.
The entire code for the project is available on this GitHub repo.
Let’s get started!
To follow along with this tutorial, you’ll need a recent version of Node installed on your PC. If this isn’t the case, then head over to the Node home page and download the correct binaries for your system. Alternatively, you might consider using a version manager to install Node. We have a tutorial on using a version manager here.
Node comes bundled with npm, a package manager for JavaScript, with which we’re going to install some of the libraries we’ll be using. You can learn more about using npm here.
You can check that both are installed correctly by issuing the following commands from the command line:
node -v
> 12.19.0
npm -v
> 6.14.8
With that done, let’s start off by creating a new React project with the Create React App tool. You can either install this globally, or use npx, like so:
npx create-react-app react-router-demo
When this has finished, change into the newly created directory:
cd react-router-demo
The React Router library comprises three packages: react-router, react-router-dom, and react-router-native. The core package for the router is react-router, whereas the other two are environment specific. You should use react-router-dom if you’re building a website, and react-router-native if you’re in a mobile app development environment using React Native.
Use npm to install react-router-dom:
npm install react-router-dom
Then start the development server with this:
npm run start
Congratulations! You now have a working React app with React Router installed. You can view the app running at http://localhost:3000/.
Now let’s familiarize ourselves with a basic React Router setup. To do this, we’ll make an app with three separate views: Home, Category and Products.
Router ComponentThe first thing we’ll need to do is to wrap our <App> component in a <Router> component (provided by React Router). Since we’re building a browser-based application, we can use two types of router from the React Router API:
The primary difference between them is evident in the URLs they create:
// <BrowserRouter>
http://example.com/about
// <HashRouter>
http://example.com/#/about
The <BrowserRouter> is the more popular of the two because it uses the HTML5 History API to keep your UI in sync with the URL, whereas the <HashRouter> uses the hash portion of the URL (window.location.hash). If you need to support legacy browsers that don’t support the History API, you should use <HashRouter>. Otherwise <BrowserRouter> is the better choice for most use cases. You can read more about the differences here.
So, let’s import the BrowserRouter component and wrap it around the App component:
// src/index.js
import React from "react";
import ReactDOM from "react-dom";
import App from "./App";
import { BrowserRouter } from "react-router-dom";
ReactDOM.render(
<BrowserRouter>
<App />
</BrowserRouter>,
document.getElementById("root")
);
The above code creates a history instance for our entire <App> component. Let’s look at what that means.
The
historylibrary lets you easily manage session history anywhere JavaScript runs. Ahistoryobject abstracts away the differences in various environments and provides a minimal API that lets you manage the history stack, navigate, and persist state between sessions. — React Training docs
Each <Router> component creates a history object that keeps track of the current location (history.location) and also the previous locations in a stack. When the current location changes, the view is re-rendered and you get a sense of navigation. How does the current location change? The history object has methods such as history.push and history.replace to take care of that. The history.push method is invoked when you click on a <Link> component, and history.replace is called when you use a <Redirect>. Other methods — such as history.goBack and history.goForward — are used to navigate through the history stack by going back or forward a page.
Moving on, we have Links and Routes.
Link and Route ComponentsThe <Route> component is the most important component in React Router. It renders some UI if the current location matches the route’s path. Ideally, a <Route> component should have a prop named path, and if the path name matches the current location, it gets rendered.
The <Link> component, on the other hand, is used to navigate between pages. It’s comparable to the HTML anchor element. However, using anchor links would result in a full page refresh, which we don’t want. So instead, we can use <Link> to navigate to a particular URL and have the view re-rendered without a refresh.
Now we’ve covered everything you need to make our app work. Update src/App.js as follows:
import React from "react";
import { Link, Route, Switch } from "react-router-dom";
const Home = () => (
<div>
<h2>Home</h2>
</div>
);
const Category = () => (
<div>
<h2>Category</h2>
</div>
);
const Products = () => (
<div>
<h2>Products</h2>
</div>
);
export default function App() {
return (
<div>
<nav className="navbar navbar-light">
<ul className="nav navbar-nav">
<li>
<Link to="/">Home</Link>
</li>
<li>
<Link to="/category">Category</Link>
</li>
<li>
<Link to="/products">Products</Link>
</li>
</ul>
</nav>
{ /* Route components are rendered if the path prop matches the current URL */}
<Route path="/"><Home /></Route>
<Route path="/category"><Category /></Route>
<Route path="/products"><Products /></Route>
</div>
);
}
Here, we’ve declared the components for Home, Category and Products inside App.js. Although this is okay for now, when a component starts to grow bigger, it’s better to have a separate file for each component. As a rule of thumb, I usually create a new file for a component if it occupies more than 10 lines of code. Starting from the second demo, I’ll be creating a separate file for components that have grown too big to fit inside the App.js file.
Inside the App component, we’ve written the logic for routing. The <Route>‘s path is matched with the current location and a component gets rendered. Previously, the component that should be rendered was passed in as a second prop. However, recent versions of React Router have introduced a new route rendering pattern, whereby the component(s) to be rendered are children of the <Route>.
Here / matches both / and /category. Therefore, both the routes are matched and rendered. How do we avoid that? You should pass the exact prop to the <Route> with path='/':
<Route exact path="/">
<Home />
</Route>
If you want a route to be rendered only if the paths are exactly the same, you should use the exact prop.
To create nested routes, we need to have a better understanding of how <Route> works. Let’s look at that now.
As you can read on the React Router docs, the recommended method of rendering something with a <Route> is to use children elements, as shown above. There are, however, a few other methods you can use to render something with a <Route>. These are provided mostly for supporting apps that were built with earlier versions of the router before hooks were introduced:
component: when the URL is matched, the router creates a React element from the given component using React.createElement.render: handy for inline rendering. The render prop expects a function that returns an element when the location matches the route’s path.children: this is similar to render, in that it expects a function that returns a React component. However, children gets rendered regardless of whether the path is matched with the location or not.The path prop is used to identify the portion of the URL that the router should match. It uses the Path-to-RegExp library to turn a path string into a regular expression. It will then be matched against the current location.
If the router’s path and the location are successfully matched, an object is created which is called a match object. The match object contains more information about the URL and the path. This information is accessible through its properties, listed below:
match.url: a string that returns the matched portion of the URL. This is particularly useful for building nested <Link> components.match.path: a string that returns the route’s path string — that is, <Route path="">. We’ll be using this to build nested <Route> components.match.isExact: a Boolean that returns true if the match was exact (without any trailing characters).match.params: an object containing key/value pairs from the URL parsed by the Path-to-RegExp package.Note that when using the component prop to render a route, the match, location and history route props are implicitly passed to the component. When using the newer route rendering pattern, this is not the case.
For example, take this component:
const Home = (props) => {
console.log(props);
return (
<div>
<h2>Home</h2>
</div>
);
};
Now render the route like so:
<Route exact path="/" component={Home} />
This will log the following:
{
history: { ... }
location: { ... }
match: { ... }
}
But now instead render the route like so:
<Route exact path="/"><Home /></Route>
This will log the following:
{}
This might seem disadvantageous at first, but worry not! React v5.1 introduced several hooks to help you access what you need, where you need it. These hooks give us new ways to manage our router’s state and go quite some way to tidying up our components.
I’ll be using some of these hooks throughout this tutorial, but if you’d like a more in-depth look, check out the React Router v5.1 release announcement. Please also note that hooks were introduced in version 16.8 of React, so you’ll need to be on at least that version to use them.
Switch ComponentBefore we head to the demo code, I want to introduce you to the Switch component. When multiple <Route>s are used together, all the routes that match are rendered inclusively. Consider this code from demo 1. I’ve added a new route to demonstrate why <Switch> is useful:
<Route exact path="/"><Home /></Route>
<Route path="/category"><Category /></Route>
<Route path="/products"><Products /></Route>
<Route path="/:id">
<p>This text will render for any route other than '/'</p>
</Route>
If the URL is /products, all the routes that match the location /products are rendered. So, the <Route> with path /:id gets rendered along with the <Products> component. This is by design. However, if this is not the behavior you’re expecting, you should add the <Switch> component to your routes. With <Switch>, only the first child <Route> that matches the location gets rendered:
<Switch>
<Route exact path="/"><Home /></Route>
<Route path="/category"><Category /></Route>
<Route path="/products"><Products /></Route>
<Route path="/:id">
<p>This text will render for any route other than those defined above</p>
</Route>
</Switch>
The :id part of path is used for dynamic routing. It will match anything after the slash and make this value available in the component. We’ll see an example of this at work in the next section.
Now that we know all about the <Route> and <Switch> components, let’s add nested routes to our demo.
Continue reading React Router v5: The Complete Guide on SitePoint.
In-game chats were flooded with messages from somebody who tried to coerce players into subscribing to a dubious YouTube channel
The post ‘Among Us’ players hit by major spam attack appeared first on WeLiveSecurity
Starting a new business is an exciting time. But it can also be a busy and stressful time. Of course,
Easy Ways to Ensure Your New Business is Protected on Latest Hacking News.
If you’re wondering what tips to improve your website design would be best for you, keep reading. As you know
Few Easy Tips to Improve Your Website Design on Latest Hacking News.
Researchers found repeated successful attempts by criminals to bypass Apple’s app notarization – security check for apps outside Mac App
Malicious Apps Repeatedly Bypassed Apple App Notarization on Latest Hacking News.
One more time, a devastating cyberattack has hit a corporate giant. This time, the victim is a French IT firm
French IT Firm Sopra Steria Suffered Ransomware Attack on Latest Hacking News.
Weeks before the US election 2020, Georgia Hall County suffered a ransomware attack on its voting system. Their IT systems
Georgia County Voting System Suffered Ransomware Attack on Latest Hacking News.
Google has recently removed three different Android apps for kids for violating the data collection policy. The apps had millions
Google Removed Three Kids Android Apps For Data Collection Violations on Latest Hacking News.
Mozilla Firefox now plans to roll out the much-awaited site isolation feature for user testing. Users can presently experience this
Firefox Brings Site Isolation Feature For Testing In Nightly Builds on Latest Hacking News.
With the latest Chrome release, Google has addressed a serious zero-day vulnerability alongside other bugs. Update your browser at the
Latest Google Chrome Update Addressed Actively Exploited Zero-Day on Latest Hacking News.
A serious vulnerability has been discovered in the Waze app that could allow tracking other users’ locations in real-time. The
Waze App Vulnerability Could Allow Tracking Users’ Location on Latest Hacking News.
Mobile users are exposed to a serious security problem due to vulnerable browsers on their devices. Security researchers have disclosed
Multiple Mobile Browsers Suffer Address Bar Spoofing Vulnerabilities on Latest Hacking News.
Google has recently removed two malicious adblockers from the web store after they were found collecting user data. Uninstall them
Google Remove Malicious Adblockers From Web Store For Collecting User Data on Latest Hacking News.
Since the time gold coins were used until the present time when eWallets and eBanking prevail, lots of processes and
What are typical payment terms? What are alternative payment methods? on Latest Hacking News.
Because of the various licensing agreements that Netflix has in place with the owners of the content that they show
Why You Can’t Use Avast SecureLine VPN With Netflix on Latest Hacking News.
In today’s digital age, a secure website for your businesses is more than necessary. You may think that your portal
6 Security Tips to Protect Your Website from Hackers on Latest Hacking News.
Technology is becoming more portable each day, and most people can’t imagine themselves a day without gadgets or modern devices
Qualities to Look For When Buying a Laptop on Latest Hacking News.
In addition to stressful exams, long lectures, and COVID-19 fears, university students must also be on the lookout for potential
Universities Back on Iranian Hackers’ Radar as the School Year Begins on Latest Hacking News.
Software application has now become a discipline of professional work based on the rather high demand of market overview around
Top 7 Types of software development on Latest Hacking News.
Security challenges for connected medical devices – Zero-day in Chrome gets patched – How to avoid USB drive security woes
The post Week in security with Tony Anscombe appeared first on WeLiveSecurity
These days, software engineering and creating computer programs are need regions, for which numerous understudies pick foreign instruction. Schools the world over offer understudies state-of-the-art coding courses that coordinate the most recent industry patterns and genuine understudy needs. What’s more, the understudies are given the most recent hardware and programming.
Because of the prominence of computer education, programs in the field of creating computer programs are currently offered in a colossal number of colleges and universities around the globe, so picking the correct course and instructive establishment can be troublesome. We will enlighten you regarding a few colleges and courses that are among the best for examining writing computer programs around the work.

The Stanford University software engineering division was set up in 1965. The faculty offers four-year certification in scientific studies’, master of science, and a specialist of theory.
The faculty embraces research in numerous regions, including man-made brainpower, mechanical technology, establishments of software engineering, logical registering, and programming frameworks. There is likewise a solid accentuation on interdisciplinary exploration across science, hereditary qualities, etymology, development, and medication, among others.
The home of the software engineering division is the Gates Computer Science Building, named after Bill Gates, who gave $6 million to the institution.
That university of such level requires high academic performance from its students. It may be a goal, which is quite difficult to achieve, especially if you want not only to study during student years but live the full life. So, we offer you to note down an essay writing service, that will help you with any difficulties during the student years just after your clicking on the “do my assignment” button.
Many believe MIT to be the main science school on the planet. The numerous elements that add to its prosperity remember its area for the Boston region, which secures its arm with first-class schools like Harvard, Boston College, Boston University, and Tufts. Notwithstanding its relationship with this esteemed organization, MIT flaunts 63 Nobel Prize victors and a $16.4 billion blessing.
Offering the absolute best undergrad software engineering programs, its Department of Electrical Engineering and Computer Science, MIT runs a few top-notch PC research focuses, for example, its biggest exploration lab, the Artificial Intelligence Laboratory. Various headways have originated from this lab, including the principal sound chess program and a great part of the innovation that was essential to the web. What’s more, MIT fills in as an innovator in nanotechnologies, data hypothesis, and bioinformatics. Obviously, MIT’s software engineering faculty has created numerous acclaimed graduated class.
The University of Iowa offers plenty of science degrees through its School of Engineering. It also has research laboratories and may be proud of famous graduates. It is a bit cheaper than other universities on the list but it does not make its quality lower.
At the point when he established CMU, Andrew Carnegie needed to apply similar sober-minded rules that shot his innovative endeavors to the hard sciences. Since its establishment in 1900, the organization has procured its place among the top exploration colleges through its attention on development and inventiveness. Positioned first in the country by U.S. News and World Report, CMU’s School of Computer Science added to the advancement of automated innovation and programming utilized on the Mars meanderers. Different center regions of exploration inside the division incorporate accident evasion innovation in vehicles and at-home help for the older.
As anyone might expect, CMU has delivered numerous elite graduated classes; these incorporate John Nash, whose life was the reason for the mainstream film A Beautiful Mind, and Professor Scott Falhman, who made the emoji.
This institution is situated in Singapore. This college was set up in 1991. Nanyang Technological University is a research establishment. Furthermore, it is likewise one of the top Asian colleges. They likewise got the best 6th position in Asia. It likewise held the best positions on the worldwide ratings.
Senior understudies of the specialty “Software engineering” – Specialization “Data Technologies of Design” have the occasion to go through practical studying in the nations of the European Union. fifth and sixth-year understudies may get a grant. All understudies who wish can turn into an individual from the Erasmus European Academic Exchange Program, inside which a couple of semesters learn at one of the colleges of the European Union. Along these lines, it demonstrates that it is a merited peace organization with high evaluating.
These days you have a great variety of universities to choose from. Most of them will give you the basic knowledge of computer sciences, but universities from our list will give you the kind of knowledge you can immediately apply in practice. So, it is enough thinking, apply to one of the universities from our list!
The post 5 Best Universities to Study Computer Science appeared first on The Crazy Programmer.
Why are connected medical devices vulnerable to attack and how likely are they to get hacked? Here are five digital chinks in the armor.
The post Securing medical devices: Can a hacker break your heart? appeared first on WeLiveSecurity
Scammers even run their own dark-web “travel agencies”, misusing stolen loyalty points and credit card numbers
The post Fraudsters crave loyalty points amid COVID‑19 appeared first on WeLiveSecurity
Recent research has demonstrated a phantom attack that fools self-driving cars by displaying virtual objects. Such attacks can trigger sudden
Phantom Attack Bluffs Self Driving Cars By Displaying Simulated Objects on Latest Hacking News.
One more vulnerable WordPress plugin requires immediate attention from the users. This time, the flaw appeared in the TI WooCommerce
TI WooCommerce Wishlist WP Plugin Flaw Could Allow Site Takeovers on Latest Hacking News.

Have you ever considered improving the learnability of your product or website? Perhaps it’s your first time reading about the concept of learnability. It’s not an easy task to build a learnable website, as it requires some experimentation and A/B testing.
Learnability’s goal is to design a clear interface that users can quickly pick up and understand. Ideally, there’s no need for documentation to educate your users on how to use your product.
Luckily, many techniques exist to create a learnable interface. This article shows you five best practices you can use to provide a more learnable interface to your users.
But first, let’s make the point clear why learnability matters.

Now, why does learnability matter? There are various reasons why you should consider providing a more learnable user interface.
First of all, users can adopt a new interface much quicker. Therefore, they can accomplish their goal using your tool much quicker. In other words, they can receive more value from your tool. Moreover, there’s little need for documentation or an extensive support center. Your goal is to reduce the number of support requests by providing a clear interface.
That’s not all! Think about customer experience. A user who can quickly learn your tool will have a better experience. In the end, the user wants to receive value within the least amount of time possible. They don’t want to spend a lot of time learning a new tool.
Lastly, learnability matters for your retention rate. A complex interface will scare users. Often, they’ll look for easier alternatives that provide them with the same value.
Now that we understand the importance of learnability, let’s explore five best practices to enhance learnability.
First, let’s discuss the importance of consistency. Google has nailed consistency through its Material Design to give all of its products a similar look. Therefore, when users switch between Google’s products, it’s much easier to understand how the new product works.
Why? Users have seen this design before and know how to interact with it. Let’s compare the interface of both Google Drive and Gmail. Note the similarities in the positioning of elements such as the search bar, menu, and action button.

For example, Google Drive has a big call to action button with the text “New” to create a new file or folder. If we compare this with Gmail, we find the same call to action button “Compose” to create a new email. This allows a user who’s new to Gmail but frequently uses Google Drive to quickly understand the purpose of this large button.

In short, consistent interfaces are predictable interfaces. This predictability leads to learnable patterns. This applies to everything, ranging from sidebar menus to icon usage, or even link color.
Feedback is one of those keywords you find in every UI design book. One of the most rudimental forms of feedback is hyperlink feedback.
A hyperlink can have three different states. First of all, a hyperlink sits in its normal state. When the user hovers the hyperlink with its cursor, the link color changes or the user sees a small transition animation. This small feedback moment tells the user that the element is clickable. Once the hyperlink has been clicked, you’ll see its active state. Again, this is a form of feedback to tell the user that the click request has been received and is being processed.

Feedback can be very subtle. We refer to this as micro-interactions. Micro-interactions can take the shape of:
These micro-interactions are crucial, as a user needs evidence that what they’ve done affected the page. Imagine you click a button to submit a form and the button doesn’t provide any sort of feedback. In other words, the page remains static. I bet you’ll hit the submit button a second time because you didn’t receive any evidence of your actions.
Therefore, be kind, and provide feedback to your users. It will make their experience so much nicer and less confusing.
Continue reading Learnability in Web Design: 5 Best Practices on SitePoint.

Webpack has established itself as an indispensable part of the JavaScript toolchain. It has over 55,000 stars on GitHub and is used by many of the big players in the JavaScript world, such as React and Angular.
However, you don’t need to be using a front-end framework, or be working on a large-scale project to take advantage of it. Webpack is primarily a bundler, and as such you can also use it to bundle just about any resource or asset you care to think of.
In this article, I’m going to show you how to install and configure webpack, then use it to create minified bundles for a simple static site with a handful of assets.
Good question. Glad you asked!
One of the reasons for doing this is to minimize the number of HTTP requests you make to the server. As the average web page grows, you’ll likely include jQuery (yes, it’s still popular in 2020), a couple of fonts, a few plugins, as well as various style sheets and some JavaScript of your own. If you’re making a network request for each of these assets, things soon add up and your page can become sluggish. Bundling your code can go some way to mitigating this problem.
Webpack also makes it easy to minify your code, further reducing its size, and it lets you write your assets in whatever flavor you desire. For example, in this article I’ll demonstrate how to have webpack transpile modern JavaScript to ES5. This means you can write JavaScript using the latest, most up-to-date syntax (although this might not be fully supported yet), then serve the browsers ES5 that will run almost everywhere.
And finally, it’s a fun learning exercise. Whether or not you employ any of these techniques in your own projects is down to you, but by following along you’ll get a firm understanding of what webpack does, how it does it and whether it’s a good fit for you.
The first thing you’ll need is to have Node and npm installed on your computer. If you haven’t got Node yet, you can either download it from the Node website, or you can download and install it with the aid of a version manager. Personally, I much prefer this second method, as it allows you to switch between multiple versions of Node and it negates a bunch of permissions errors, which might otherwise see you installing Node packages with admin rights.
We’ll also need a skeleton project to work with. Here’s one I made earlier. To get it running on your machine, you should clone the project from GitHub and install the dependencies:
git clone https://github.com/sitepoint-editors/webpack-static-site-example
cd webpack-static-site-example
npm install
This will install jQuery, plus Slick Slider and Lightbox2 — two plugins we’ll be using on the site — to a node_modules folder in the root of the project.
After that, you can open index.html in your browser and navigate the site. You should see something like this:
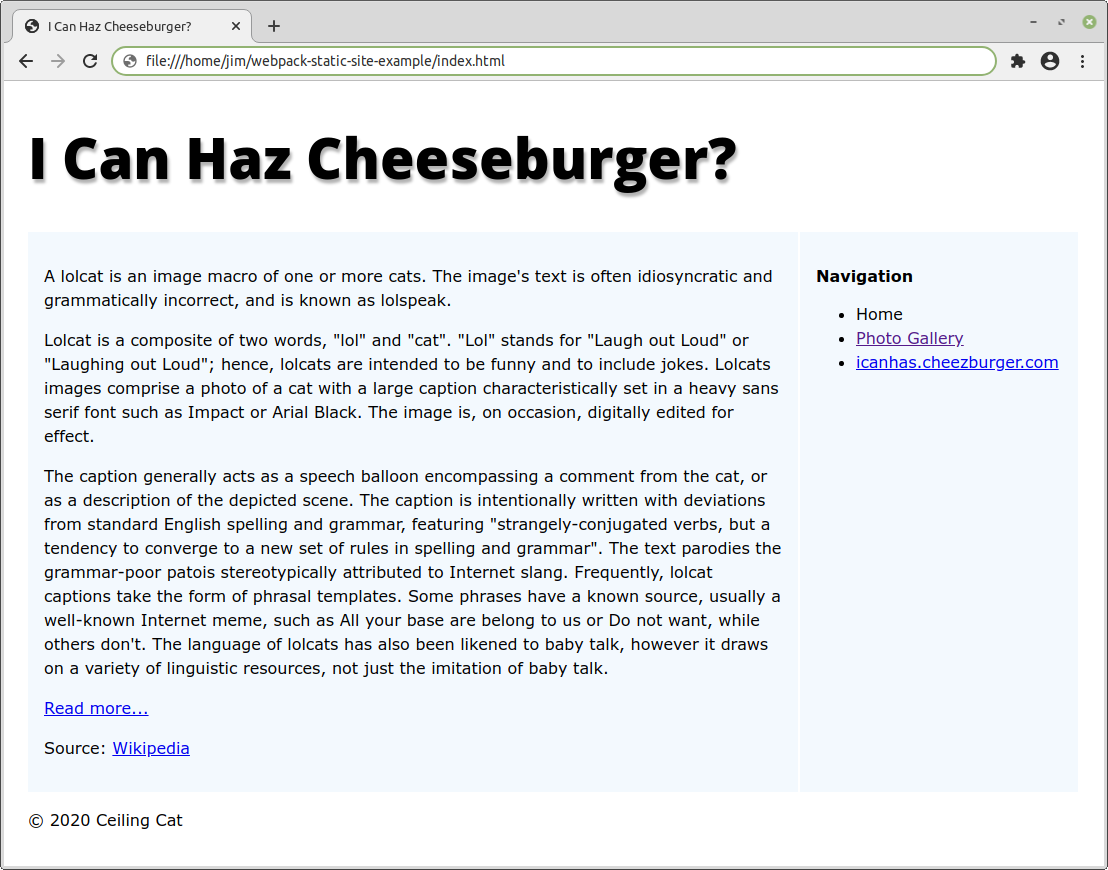
If you need help with any of the steps above, why not head over to our forums and post a question.
The next thing we’ll need to do is to install webpack. We can do this with the following command:
npm install webpack webpack-cli --save-dev
This will install webpack and the webpack CLI and add them to the devDependency section of your package.json file:
"devDependencies": {
"webpack": "^5.1.3",
"webpack-cli": "^4.0.0"
}
Next, we’ll make a dist folder which will contain our bundled JavaScript:
mkdir dist
Now we can try and run webpack from the command line to see if it is set up correctly:
./node_modules/webpack/bin/webpack.js ./src/js/main.js --output-filename=bundle.js --mode=development
What we’re doing here is telling webpack to bundle the contents of src/js/main.js into dist/bundle.js. If everything is installed correctly, you should see something like this output to the command line:
asset bundle.js 1.04 KiB [emitted] (name: main)
./src/js/main.js 192 bytes [built] [code generated]
webpack 5.1.3 compiled successfully in 45 ms
And webpack will create a bundle.js file in the dist folder. If you have a look at that file in your text editor of choice, you’ll see a bunch of boilerplate and the contents of main.js at the bottom.
If we had to type all of the above into the terminal every time we wanted to run webpack, that’d be quite annoying. So let’s create an npm script we can run instead.
In package.json, alter the scripts property to look like this:
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "webpack ./src/js/main.js --output-filename=bundle.js --mode=development"
},
Notice how we can leave out the full path to the webpack module, as when run from a script, npm will automatically look for the module in the node_modules folder. Now when you run npm run build, the same thing should happen as before. Cool, eh?
Notice how we’re passing the path of the file to bundle and the path of the output file as arguments to webpack? Well, we should probably change that and specify these in a configuration file instead. This will make our life easier when we come to use loaders later on.
Create a webpack.config.js file in the project root:
touch webpack.config.js
And add the following code:
module.exports = {
entry: './src/js/main.js',
mode: 'development',
output: {
path: `${__dirname}/dist`,
filename: 'bundle.js',
},
};
And change the npm script to the following:
"scripts": {
...
"build": "webpack"
},
In webpack.config.js we’re exporting a configuration object, which specifies the entry point, the mode webpack should run in (more on that later), and the output location of the bundle. Run everything again and it should all still work as before.
Now that we have webpack generating a bundle for us, the next thing we need to do is to include it somewhere. But first, let’s create a different entry point, so that we can list the assets we want webpack to bundle for us. This will be a file named app.js in the src/js directory:
touch src/js/app.js
Add the following to app.js:
require('./main.js');
And change the webpack config thus:
entry: './src/js/app.js',
Run npm run build again to recreate the bundle. Everything should work as before.
Now, if you have a look at index.html you’ll notice that there’s not much going on JavaScript-wise. At the bottom of the file we are including jQuery and a file called main.js, which is responsible for showing more information when you click the Read more… link.
Let’s edit index.html to include the bundle instead of main.js. Look at the bottom of the file. You should see:
<script src="./node_modules/jquery/dist/jquery.min.js"></script>
<script src="./src/js/main.js"></script>
</body>
</html>
Change this to:
<script src="./node_modules/jquery/dist/jquery.min.js"></script>
<script src="./dist/bundle.js"></script>
</body>
</html>
Refresh the page in the browser and satisfy yourself that the Read more… link still works.
Next, let’s add jQuery to the bundle. That will reduce the number of HTTP requests the page is making. To do this, we have to alter the app.js file like so:
window.$ = require('jquery');
require('./main.js');
Here we’re requiring jQuery, but as we installed this using npm, we don’t have to include the full path. We’re also adding its usual $ alias to the global window object, so that it’s accessible by other scripts. We’re requiring main.js after jQuery, as the former depends on the latter, and order is important.
Alter index.html to remove the jQuery script tag:
<script src="./dist/bundle.js"></script>
</body>
</html>
Run npm run build and once again, refresh the page in the browser to satisfy yourself that the Read more… link still works. It does? Good!
Continue reading How to Bundle a Simple Static Site Using Webpack on SitePoint.